C++引用与内联函数inline
目录
1. 引用 🚀
1.1. 理论 🚀
1.1.1 定义 🚀
1.1.2. 用法 🚀
1.1.3. 引用特性 🚀
1.2. 代码深度理解 🚀
1.2.1. 权限讲解 🚀
1.2.2. 权限深度理解 🚀
1.3. 引用使用场景 🚀
1.3.1. 做参数 🚀
1.3.2. 做返回值 🚀
1.4. 引用和指针的区别 🚀
2.1. 概念 🚀
2.2. 实用 🚀
2.2 关于宏和C++的优化 🚀
C语言的入门篇进阶篇和深剖篇都整理在这里了哈。然后这里是个人主页,比点头像更好找文章哈。
作者和朋友建立的社区:非科班转码社区-CSDN社区云💖💛💙
期待hxd的支持哈🎉 🎉 🎉
最后是打鸡血环节:你只管努力,剩下的交给天意🚀 🚀 🚀

1. 引用 🚀
1.1. 理论 🚀
1.1.1 定义 🚀
引用 不是新定义一个变量,而 是给已存在变量取了一个别名 ,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
1.1.2. 用法 🚀
类型& 引用变量名(对象名) = 引用实体;
比如 int& b=a;
这里b就是a的引用(别名)
1.1.3. 引用特性 🚀
1. 引用在 定义时必须初始化 2. 一个变量可以有多个引用(可以引用常量) 3. 引用一旦引用一个实体,再不能引用其他实体
1.2. 代码深度理解 🚀
1.2.1. 权限讲解 🚀
1.2.2. 权限深度理解 🚀
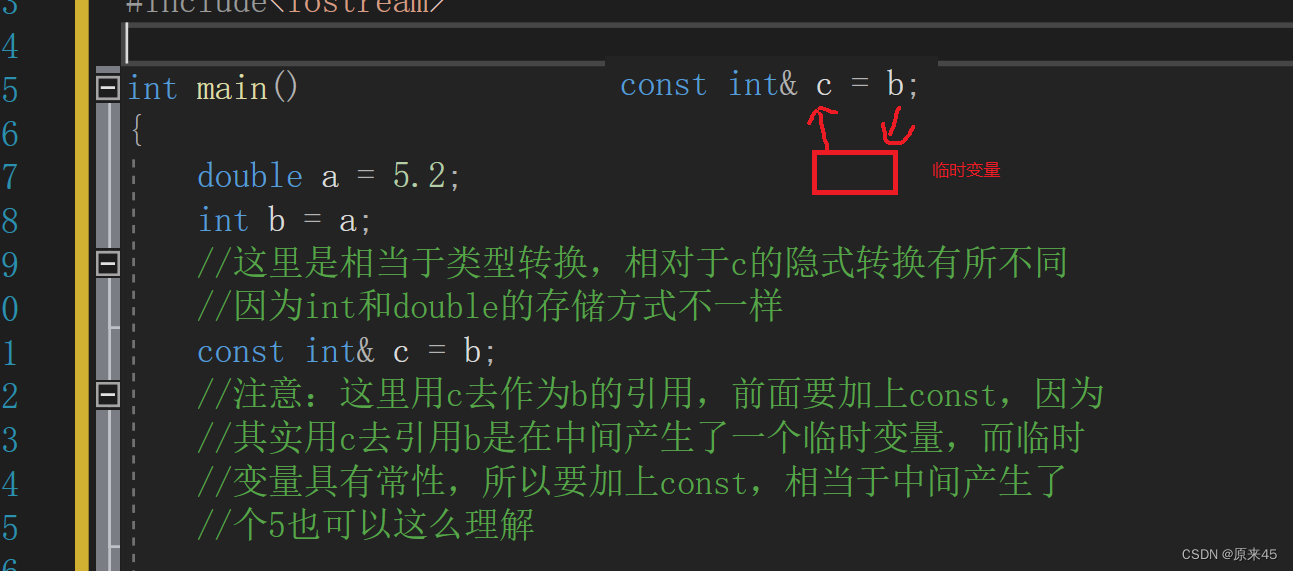
但是对于为什么int b =a 不加const是因为这是赋值,b的改变不影响a
而且现在c是这个临时变量的别名,不是b的了

1.3. 引用使用场景 🚀
1.3.1. 做参数 🚀
1. 输出型参数(比如熟悉的returnSize,可以用引用去接受,传实参的时候不用地址了)
2. 减少拷贝,提升效率(用引用接受就是实参的别名,没有开空间,就和传指针差不多的去理解)
1.3.2. 做返回值 🚀
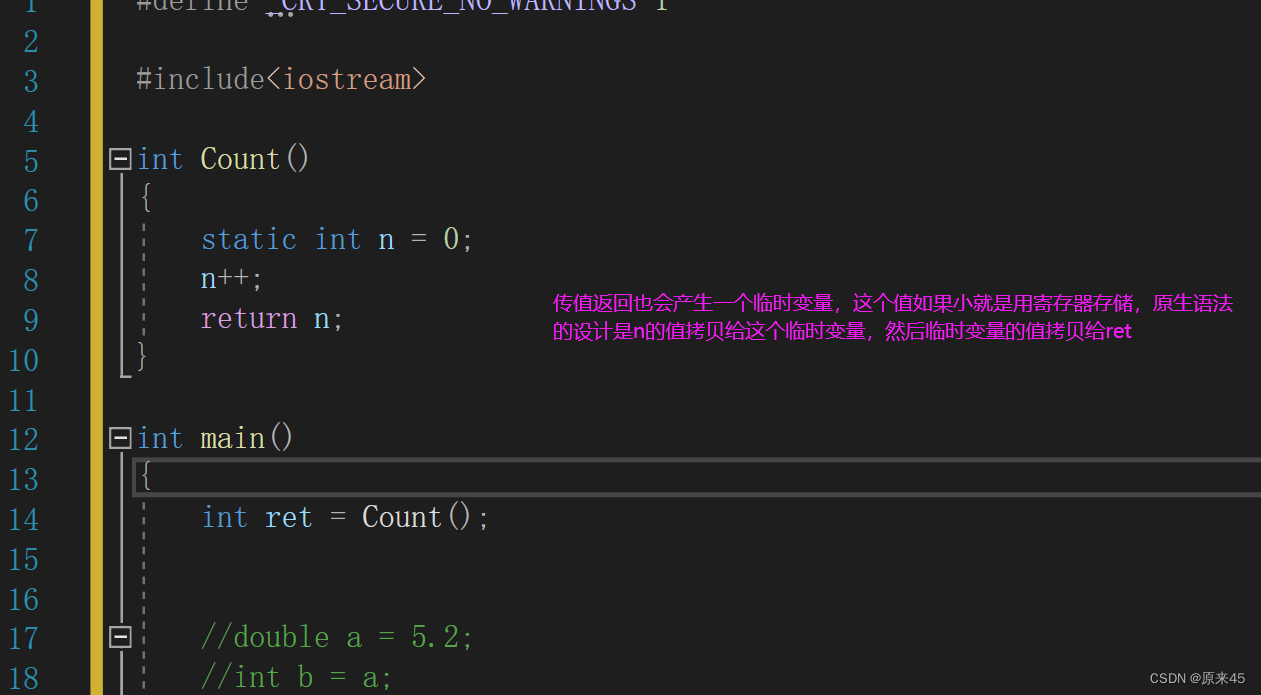
传值返回:会有一个拷贝
但是为什么要产生临时变量呢?
因为并不是都会像我们这样产生一个静态的局部变量然后去返回,而且确实静态变量在实际中是很少用的,因为会产生一些线程安全的问题,要加锁很麻烦。实际中是很可能不是静态变量的,是局部变量,我们之前是学过了函数栈帧,也知道返回值是存储在寄存器的,如果现在没有那个寄存器且返回局部变量,因为我们已经出了函数栈帧,函数栈帧销毁了,也就是那个局部变量已经销毁了,所以ret就得不到要返回的值,所以编译器为了不考虑是静态变量还是局部变量,就都产生了一个临时变量去存储。(如果数据大的话其实是会在上一层函数提前开辟好空间,然后互相拷贝,了解一下就可以了)证明是用一个临时变量存储的:
加上const就不报错了 ,上面的那个图就是哈
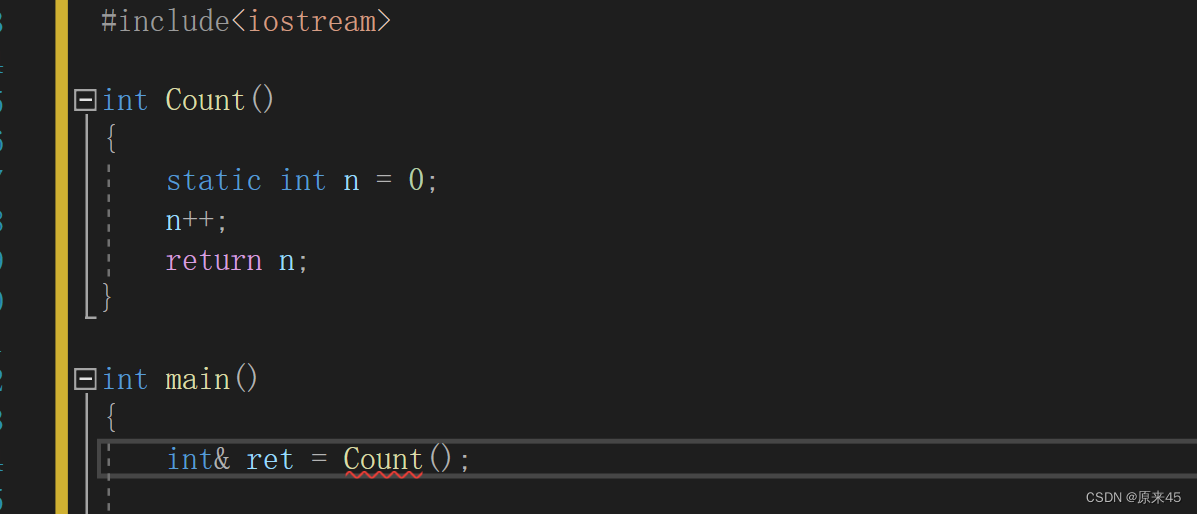
传引用返回:没有这个拷贝了,函数返回直接就是返回变量的别名
证明ret是n的别名(这里去了static,去不去一样的哈对于这个结果):
这里ret和n的地址是一样的,说明ret是n的别名
上面去掉static的虽然编译能过但是是不合法的(不安全)
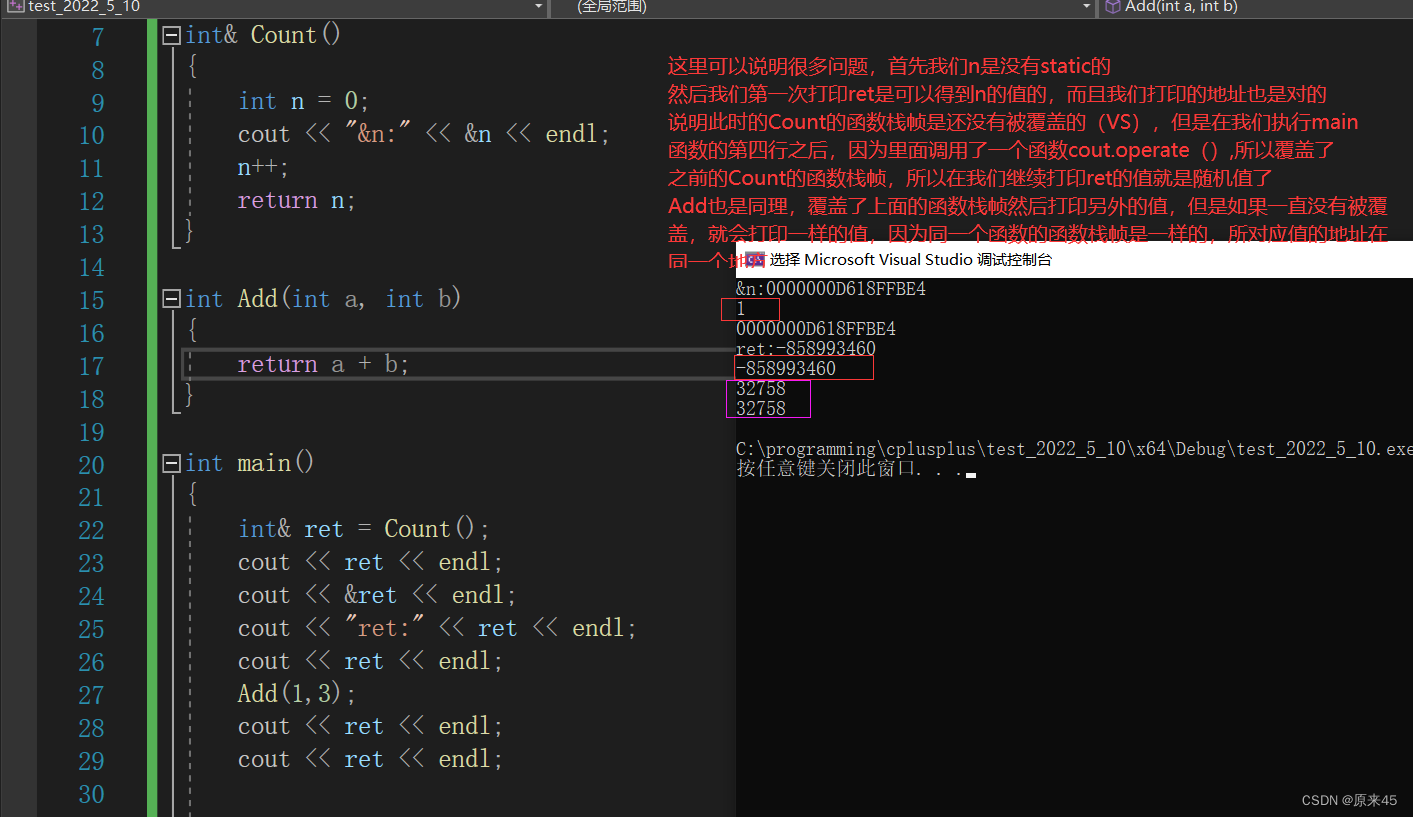
我们来看看下面代码
(上面是cout.operator()函数,写错了)
其实也可以这么理解,取的值是上一次函数调用开辟函数栈帧的结构,注意!是先传参后开辟栈帧(静态的就没有这些问题哈,因为覆盖不了了)
上面的不安全:就是值可能会变,但是如果用static就没有问题
其实总的来说:
如果函数返回时,出了函数作用域,如果返回对象还未还给系统,则可以使用引用返回,如果已 经还给系统了,则必须使用传值返回。


1.4. 引用和指针的区别 🚀
在 语法概念上 引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。 在 底层实现上 实际是有空间的,因为 引用是按照指针方式来实现 的。
引用和指针的不同点:
1. 引用 在定义时 必须初始化 ,指针没有要求 2. 引用 在初始化时引用一个实体后,就 不能再引用其他实体 ,而指针可以在任何时候指向任何一个同类型实体 3. 没有 NULL 引用 ,但有 NULL 指针 4. 在 sizeof 中含义不同 : 引用 结果为 引用类型的大小 ,但 指针 始终是 地址空间所占字节个数 (32 位平台下占4个字节 ) 5. 引用自加即引用的实体增加 1 ,指针自加即指针向后偏移一个类型的大小 6. 有多级指针,但是没有多级引用 7. 访问实体方式不同, 指针需要显式解引用,引用编译器自己处理 8. 引用比指针使用起来相对更安全

2. 内联函数 🚀
2.1. 概念 🚀
1. 以 inline 修饰 的函数叫做内联函数, 编译时 C++ 编译器会在 调用内联函数的地方展开 ,没有函数压栈的开销,内联函数提升程序运行的效率。(和c的#define有点像) 2. inline 对于编译器而言只是一个建议 ,编译器会自动优化,如果定义为 inline 的函数体内有循环 / 递归等 等,编译器优化时会忽略掉内联。 3. inline 不建议声明和定义分离,分离会导致链接错误。因为 inline 被展开,就没有函数地址了,链接就会找不到。
2.2. 实用 🚀
为什么C++会出内联函数呢,其实就是为了解决宏函数晦涩难懂,容易写错的问题,而且宏不支持调试。而inline就是解决这些哈。 当我们函数较小而调用次数较多
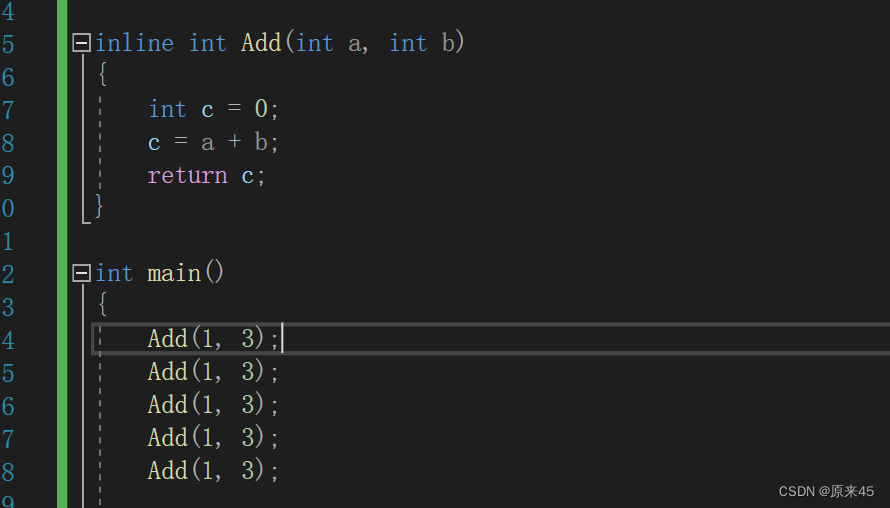

这样就会开辟大量重复的函数栈帧(有call就是有函数调用,开辟函数栈帧)
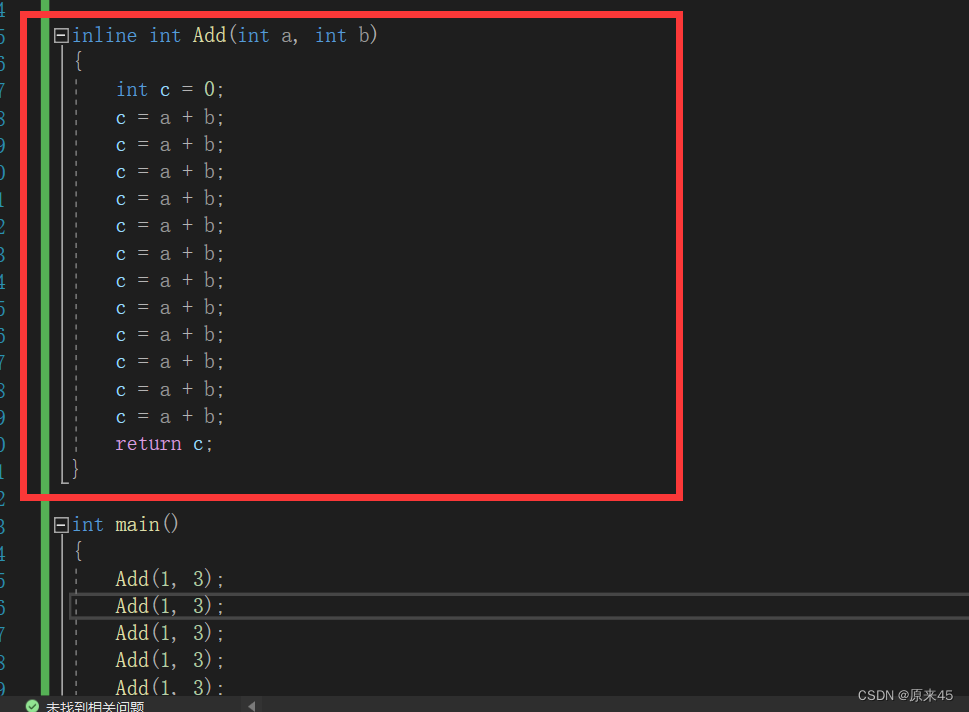
内联函数就会把调用的地方像宏一样展开(汇编指令),这样就大量减少了函数栈帧的开辟。
但是我们这里虽然用了inline但是还是有call是因为
inline默认的debug是不会展开(有call),要release或者优化,优化了就进不去了,因为没有栈帧了
解释:
如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。
查看方式: 1. 在 release 模式下,查看编译器生成的汇编代码中是否存在 call Add 2. 在 debug 模式下,需要对编译器进行设置,否则不会展开 ( 因为 debug 模式下,编译器默认不会对代码进行优化,以下给出vs2022 的设置方式 )

现在反汇编就看不到call了哈
对于编译器内联是一种建议,如果代码过长就不会接受我们的建议(一般是10行左右)


2.2 关于宏和C++的优化 🚀
宏的优缺点? 优点: 1. 增强代码的复用性。 2. 提高性能。 缺点: 1. 不方便调试宏。(因为预编译阶段进行了替换) 2. 导致代码可读性差,可维护性差,容易误用。 3. 没有类型安全的检查 。 C++ 有哪些技术替代宏 ? 1. 常量定义 换用 const 2. 函数定义 换用内联函数
最后的最后,创作不易,希望读者三连支持💖
赠人玫瑰,手有余香💖

